Ανάλυση των αποτελεσμάτων
| :construction: ΥΠΟ ΚΑΤΑΣΚΕΥΗ :construction: |
|---|
Η ανάλυση συναισθήματος με τεχνικές επεξεργασίας φυσικής γλώσσας γίνεται με το πρόγραμμα NiosTo (προφέρεται: νιώστο) (βλ. Acknowledgements)
Το NiosTo δέχεται αρχεία .xls όπου το προς ανάλυση κείμενο πρέπει να βρίσκεται
στη δεύτερη στήλη. Η δεύτερη προϋπόθεση πληρούται καθώς κατά την
κατασκευή του get-tweets.py έχει προβλεφθεί ώστε τα εξαγόμενα .csv
να έχουν το κείμενο των tweets στη δεύτερη στήλη.
Αυτό που μένει λοιπόν είναι να τα μετατρέψουμε σε .xls.
Ανοίγουμε ένα ένα τα αρχεία .csv με επεξεργαστή λογιστικών φύλλλων
(προτείνεται το LibreOffice Calc).
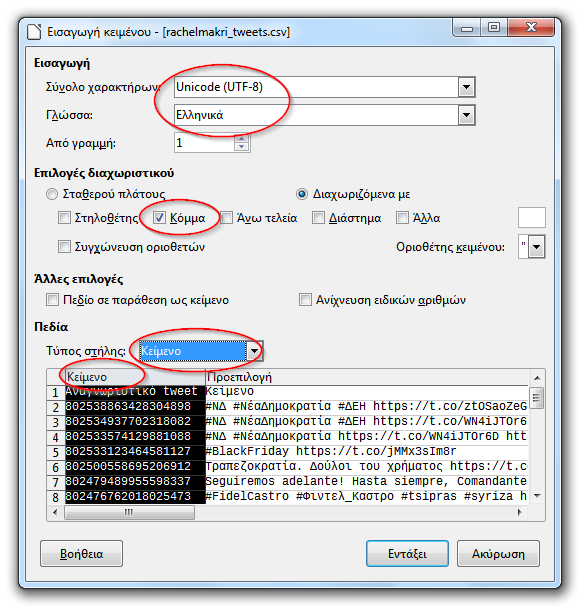
Κατά το άνοιγμα φροντίζουμε:
- το σύνολο χαρακτήρων να είναι UTF-8,
- η γλώσσα να είναι Ελληνικά, και
- το διαχωριστικό στηλών να είναι το κόμμα (
,) και κανένα άλλο (αυτό είναι σημαντικό γιατί ορισμένα tweets περιέχουν ερωτηματικά ή άλλους χαρακτήρες που χρησιμοποιούνται συνήθως ως διαχωριστικά). - Επίσης, η πρώτη στήλη με το αναγνωριστικό (id) κάθε tweet πρέπει να
μορφοποιηθεί ως κείμενο. Επιλέγουμε ολόκληρη τη στήλη κάνοντας κλικ
στην κεφαλίδα της που λέει
Προεπιλογήκαι το αλλάζουμε σεΚείμενο.
Αφού το κάθε αρχείο ανοίξει και βεβαιωθούμε ότι οι στήλες απεικονίζονται
σωστά, το αποθηκεύουμε ως .xls.
Μόλις τελειώσουμε με τα τρία αρχεία με τα tweets περνάμε στο πρόγραμμα NiosTo για να κάνουμε την ανάλυση.
Πρώτα από όλα πηγαίνουμε στο μενού File → Options και επιλέγουμε:
Language Extraction → Greek
Στη συνέχεια φορτώνουμε ένα από τα αρχεία .xls.